Informatica's New World Data Management | Informatica Data Management
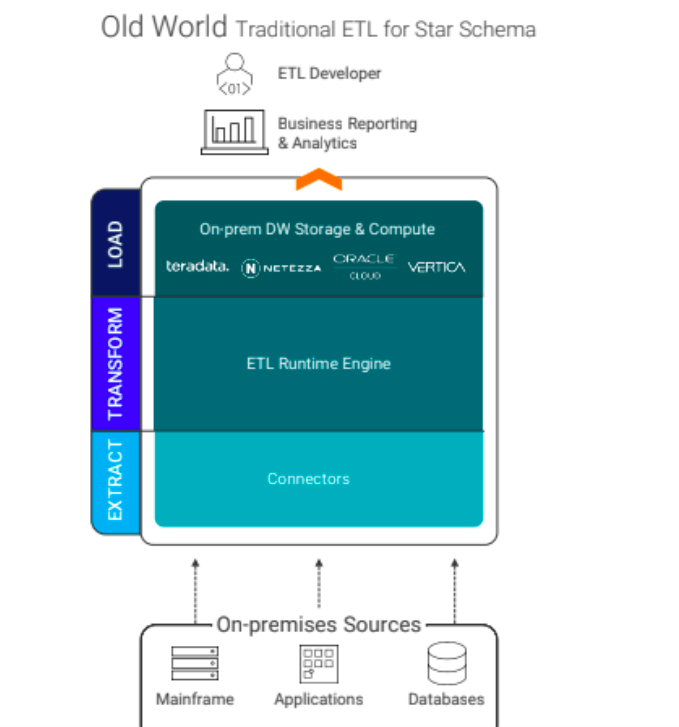
In the New World, with the separation of compute and storage, we still need a compute stack, connectors, and storage. However, the number of data sources now has fragmented and exploded to include emerging SAS cloud-native sources, real-time sensors, instruments, and more. Thus, instead of ETL, we must take all of these data and load it into Cloud-Native elastic storage, process and transform curate, and prepare it with whatever compute that we prefer, thereby supporting many more initiatives beyond business reporting and analytics like AI/ML, Streaming Analytics, and XOps, empowering a much larger array of data consumers like data engineers, citizen integrators, data scientists.
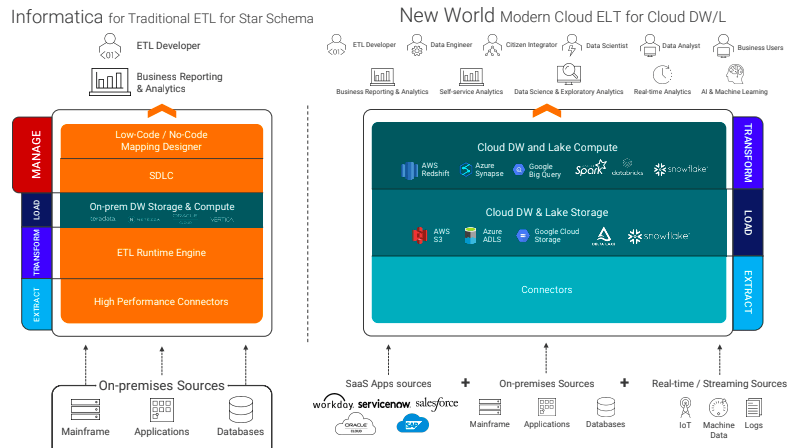
In this new world, in this new architecture, it is extract, load and transform (ELT). Informatica has reinvented with the broadest portfolio of high-performance metadata-aware connectors to extract and rapidly, massively ingest into our choice of cloud Lake storage – whether it’s AWS S3, Azure ADLS, Google Cloud Storage, Databricks, or Snowflake – leveraging ELT optimized runtime engine. Informatica has enabled through advanced pushdown optimization the deployment and processing at petabyte scale on AWS Redshift, Azure Synapse, Google BigQuery, Databricks, or Snowflake as well as their own Spark-serverless engine. Informatica has pioneered and built thier own AI-powered engine, CLAIRE, to deliver low-code/no-code, intuitive data pipeline development experiences including CI/CD DataOps and MLOps.
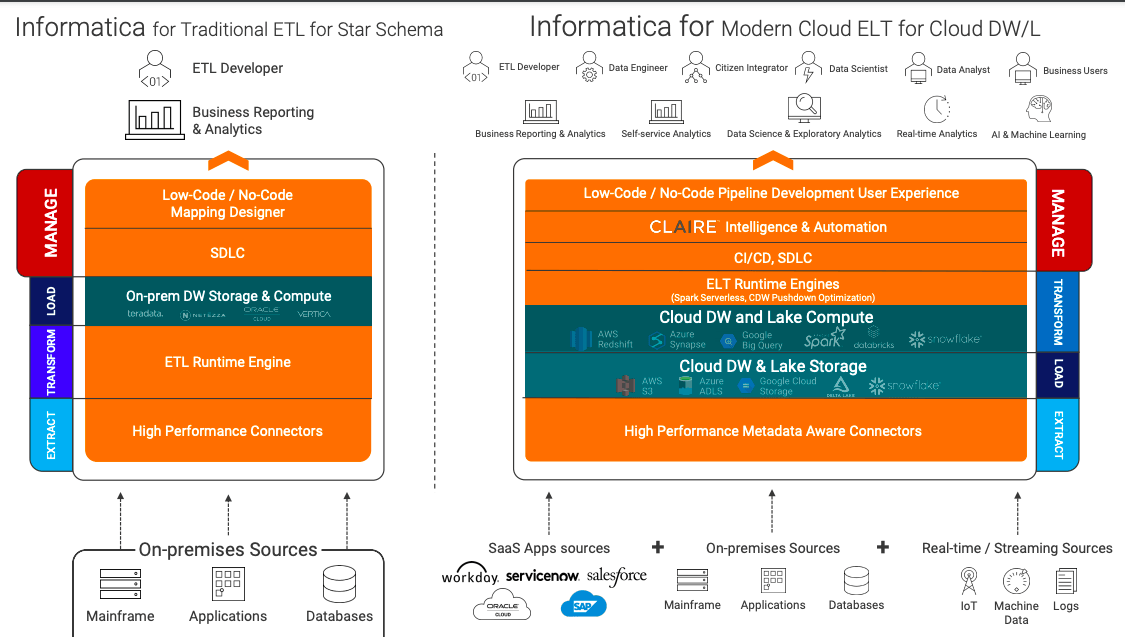
Together with Informatica, PartnerBO will help you to implement and service new world modern cloud ELT for cloud DW/L
At PartnerBO we support your growth through System & Data integration, focusing on increasing your strength from inside your organization. We help you empower yourself with new capabilities such as data quality, data management, cloud data integration, big data architecture, hospital-wide data quality governance, data security, and data archiving.
Our services are around and about Intelligent Data Platforms, which are a powerful combination of metadata intelligence and artificial intelligence, fully integrated across all aspects of data management. PartnerBO helps you in your journey to leverage
cloud,
big data, data management, governance, archiving transformations, data asset monetization, and data-driven decisions, for your business growth goals.